Redis - HyperLogLog
순방문자수(UV) 통계처리를 해야 할 일이 생겨, Redis를 통한 방법을 좀 찾아 보던 중에 흥미로운 Redis 자료 구조가 있어 기록해둔다.
먼저 사용 예를 보자.
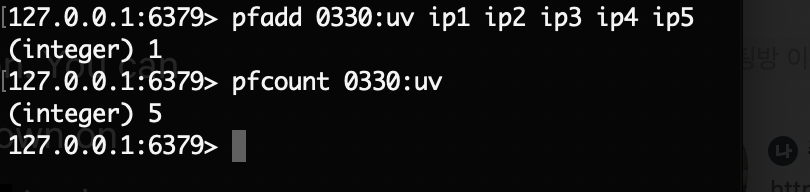
사용 예만 봤을때, Set과 같은 자료 구조로 중복 제거한 데이터의 카운트 수를 구해주는 기능으로 보인다.
허나, 방문자가 많다면 key값만 해도 많은 양의 메모리를 요구하게 된다. (방문자 카운트 연산도)
HyperLogLog는 대용량 데이터에서 중복된 값을 계산하는데 적은 비용과 빠른 속도로 계산하는 대신 약간의 오차를 허용하는 개념이다. 정확한 값을 얻는 데 필요한 비용이 높을 때 상대적으로 자원을 매우 적게 사용해 실시간으로 근삿값을 구할 수 있다면, 정확한 값 대신 근삿값이 유용할 수 있다. 가령 어떤 웹 페이지의 정확한 UV가 1억이라면 정확히 1억이라는 값을 시간이 오래 걸려 얻는 것 보다 1억에 가까운 끈삿값을 빠르게 얻는게 효율적일 수 있다.
HyperLogLog는 2007년에 발표된 알고리즘이며 Loglog Counting 알고리즘을 발전시켜 개발하였기 때문에 Hyper 접두사를 붙혔다. Redis 공식홈페이지에 의하면 0.81%의 표준 오류와 함께 키당 약 12KB의 매우 적은 양의 메모리를 사용한다고 소개하고 있다. 또한 hyperloglog의 저장 속도는 set에 비해 데이터 1백만개 기준 약 1.6배 빠른 특징이 있다고 한다.
셰익스피어 전 작품에 사용된 총 67,801개의 단어를 정확히 세려면 JAVA의 HashSet으로는 약 10MB의 메모리가 필요하다.
반면 HyperLogLog를 사용하면 결과는 정확한 값과 3%의 차이가 있지만 HashSet이 필요로 하는 메모리 크기의 1/2,500인 512바이트만 사용하는 것을 확인할 수 있다.
HyperLogLog의 이론
- 만약 동전을 여러 번 던지면서 연속으로 얻는 최대 앞명 수를 기록한다고 가정해 보자. 앞면 수를 통해서 동전을 몇 번 던졌는지 추정 할 수 있을까?
- 동전 던지기 횟수가 많을 수록 연속으로 앞면이 나타날 확률이 높아 질 것으로 거꾸로 생각해 보면 앞면의 수를 가지고 동전을 몇번 던졌는지 더 나은 추정을 할 수 있을 것이다.
- 이런 방법과 유사하게 hyperloglog(이하 hll)의 정수의 상위 비트에 대한 확률적인 접근으로, 근사치를 추정할 수 있다는 아이디어를 기반으로 한다. 어떤 정수가 있을 때 상위 첫째 비트가 0혹은 1인 정수가 올 확률은 50%를 차지한다.
- 하지만 상위 2자리로 시작하는 정수 00, 01, 10, 11로 시작하는 최대 cardinality는 전체의 25% 가 될 것이다.
- 이렇게 상위 몇 비트(b)를 사용할 것인지에 따라 레지스터(반복의 갯수)의 갯수가 결정 된다.
- 당연히 레지스터 개수를 늘이면 좀 더 정해에 가까운 추정 값을 계산할 수 있다.
개인 생각 정리
- 정리에 앞서 순방문자를 구하기 위한 방법으로 우선 redis을 이용하는 방법으로 찾아 본 이유를 언급하고자 한다.
elastic, 몽고 등 다른 방법도 있을 것이나, 페이지 방문때마다 I/O가 일어나는 일이라 in-memory 방식인 Redis가 가장 빠르고 적합할 것이라고 생각했다. 그리고 이런 류의 데이터는 시계열 데이터로 일정 시간 단위(예 : 시간별) 이전의 데이터는 rdb등에 저장해서 보여주고, 실시간 데이터는 IO 속도가 비교적 빠른 redis를 이용하는 것이 좋다고 판단했다. - redis를 이용해 순방문자 구하는 방법을 검색해보면 bitmap 자료 구조를 사용하라는 글도 많았다.
회원 아이디 index를 가진 field 에 비트 1,0을 저장하고, bitcount 연산을 통해 카운트를 구하는 방식이다.
근데 이 방법은 회원 방문자수를 구할 수는 있으나 순 방문자를 ip 기준으로 하는 경우는 좀 사용하기 힘들었다.
또한 회원 아이디가 long타입인 경우는 저장도 불가능하였다.. (내가 방법을 모르는 것일 수도 있다. 도움 주실 수 있는 분이 있다면 댓글 부탁요..^0^) - 백만 이상의 순 방문자가 접근할 수 있다는 가정으로 테스트를 해보려고 한다. 67,801개수의 경우 오차 3퍼센트라고 하니, 확률에 이용 되는 데이터 크기를 조정하여 실제 사용된 메모리양과 오차 범위를 테스트 해봐야 겠다.
완료 되는대로 github 주소 링크 해놓으려고 한다!